
ch15. Data type in DB
15.1 ~ 15.3
wordsCount: 4574
readingTime: 10 mins
viewers:
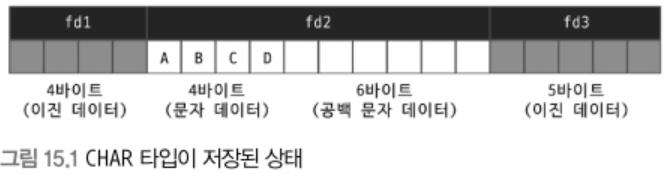
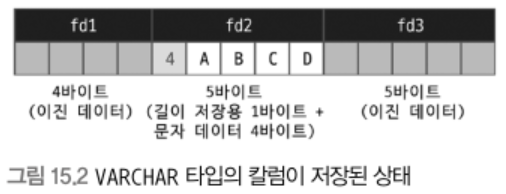
저장 공간
-
char vs varchar: 둘다 문자열을 저장할 수 있는 데이터 타입, 차이는 고정/가변 길이
- 두 타입 모두 한 글자를 저장하기 위해 사용하는 문자 집합에 따라 1 ~ 4바이트를 사용한다.
- char에 저장될 때는 추가 공간이 필요없지만 varchar에 저장할 때는 문자열의 길이를 관리하기 위한 1 ~ 2바이트의 추가 공간이 필요함
- varchar 타입의 길이가 255바이트 이하면 1바이트만 사용, 256바이트 이상이면 2바이트를 사용한다.
- varchar 타입의 최대 길이는 65536 바이트
256 * 256
- varchar 타입의 최대 길이는 65536 바이트
-
char, varchar를 결정하는 기준
- 저장되는 문자열의 길이가 비슷한지
- 컬럼의 값이 자주 변경되는지
- char 타입은 이미 준비된 공간에 값을 업데이트하면 된다.
- varchar 타입에서 길이가 더 큰 값으로 변경되면 레코드 자체를 다른 공간으로 옮겨서 저장해야 한다.
- 레코드의 이동이나 분리는 char보다 더 큰 공간이나 자원을 낭비함
-
char, varchar 키워드 뒤에 인자값 n
- 바이트 크기가 아닌 글자 크기를 명시
- 일반적으로 영어를 포함한 서구권 언어는 각 문자가 1바이트를 사용하므로 10바이트를 사용
- 한국어/일본어 같은 아시아권 언어는 각 문자가 최대 2바이트를 사용하므로 20바이트를 사용
- UTF-8과 같은 유니코드는 최대 4바이트까지 사용하므로 40바이트를 사용
저장 공간과 스키마 변경 (Online DDL)
- MySQL 서버는 데이터가 변경되는 도중에도 스키마를 변경할 수 있도록 Online DDL을 제공
- 모든 스키마 변경이 온라인으로 가능한건 아님
- 변경 작업의 특성에 따라 select는 가능, 데이터 변경은 불가능할 수 있음
- varchar 컬럼의 길이를 늘리는 작업은 작업의 길이에 따라 빠르게 처리될 수 있지만 읽기 잠금을 걸고 레코드를 복사하는 작업이 필요할 수 있음
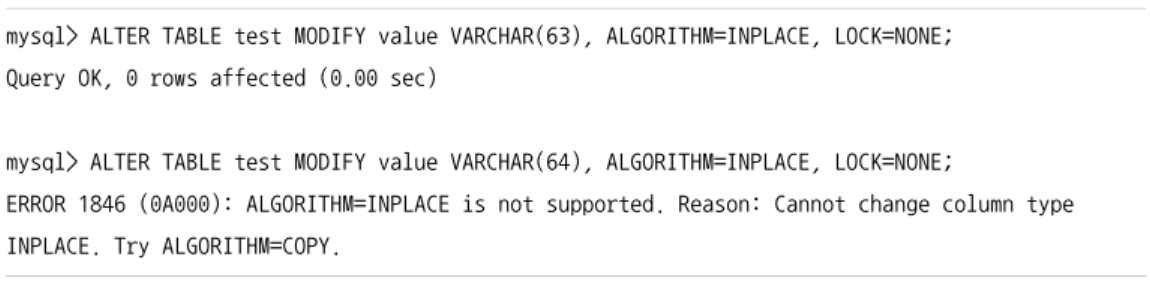
- 컬럼의 타입을 varchar(63)으로 늘리는 경우 잠금 없이 빠르게 변경될 수 있음
- varchar(64)으로 늘리는 경우 inplace 알고리즘으로 스키마 변경이 허용되지 않음
- copy 알고리즘으로 변경 -> 읽기잠금 필요, 시간도 오래걸림
- utf8mb4 문자 집합을 사용하는 varchar(60)은 최대 길이가 240바이트라서 1바이트면 된다.
- varchar(64)은 문자열의 최대인 256바이트보다 크기 때문에 2바이트로 변경되어야 한다.
- MySQL 서버는 읽기 잠금을 걸어서 데이터 변경을 막고 테이블의 레코드를 복사하는 방식으로 처리함
- varchar 타입의 길이가 크게 변경될 것으로 예상된다면 길이 저장 공간의 크기가 바뀌지 않도록 미리 조금 크게 설계하는 것이 좋음
문자 집합 (캐릭터 셋)
-
문자 집합은 문자열을 사용하는 char, varchar, text 타입의 컬럼에만 설정할 수 있음
-
MySQL에서는 MySQL 서버와 DB, 테이블 단위로 기본 문자 집합을 설정할 수 있음
- 테이블의 문자 집합을 UTF-8로 설정하면 컬럼의 문자 집합을 별도로 지정하지 않아도 UTF-8을 사용
-
최근에는 여러 나라의 언어를 동시에 지원하기 위해 utf8mb4을 사용하는 추세
-
MySQL 서버에서 사용 가능한 문자 집합은
SHOW CHARACTER SET명령으로 확인한다.
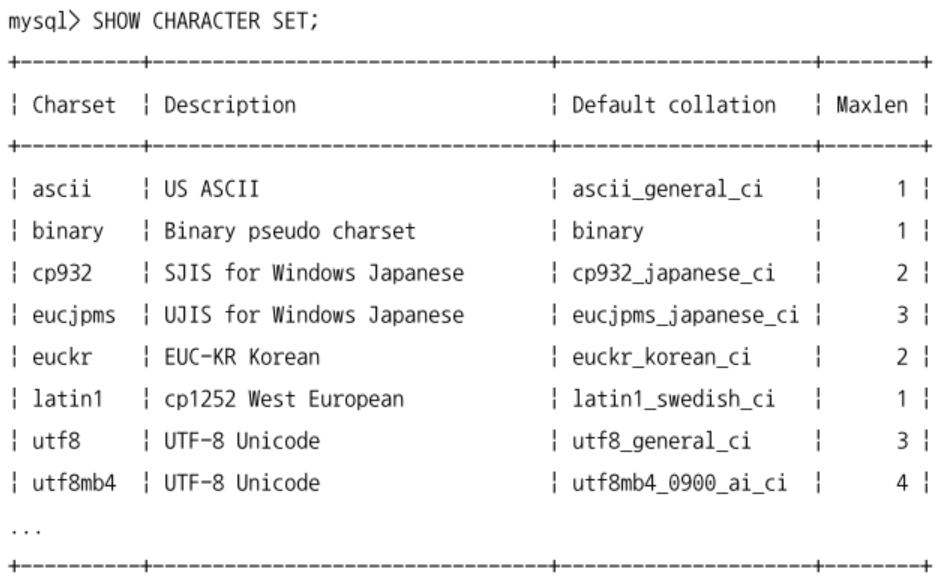
default collation컬럼에는 해당 문자 집합의 기본 콜레이션을 표시
-
MySQL에는 문자 집합을 설정하는 시스템 변수가 여러가지 있음
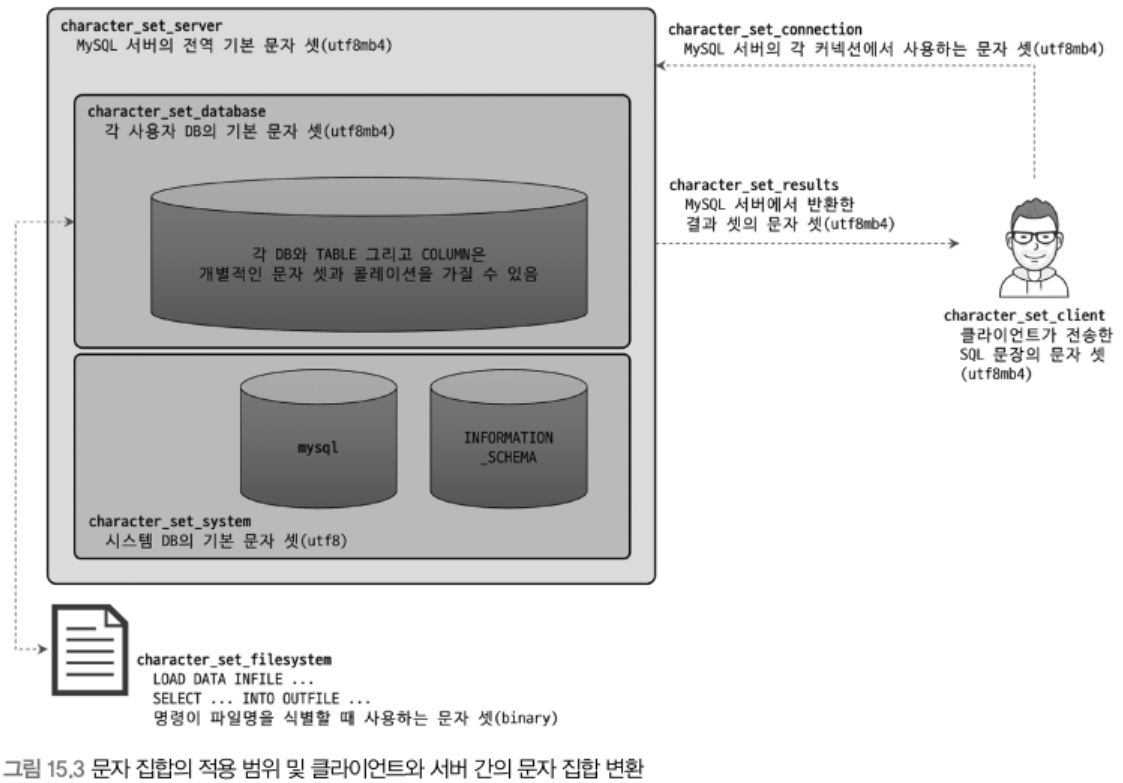
클라이언트로부터 쿼리를 요청했을 때의 문자 집합 변환
- MySQL 서버는 클라이언트로부터 받은 메시지가 character_set_client에 지정된 문자 집합으로 인코딩되어 있다고 판단하고, 받은 문자열 데이터를 character_set_connection에 정의된 문자 집합으로 변환한다.
- SQL 문장에 별도의 문자 집합이 지정된 문자열은 변환 대상이 아님
- SQL 문장에서 별도로 문자 집합을 설정하는 지정자를
인트로듀서라고 함1 2select emp_no, first_name, from employees where first_name='Matt'; select emp_no, first_name, from employees where first_name=_latin1'Matt';- 1번 쿼리의 ‘Matt’은 character_set_connection으로 문자 집합이 변환된 이후 처리
- 2번 쿼리는 인트로듀서가 사용되어 문자 집합의 변환되지 않음
- SQL 문장에서 별도로 문자 집합을 설정하는 지정자를
- SQL 문장에 별도의 문자 집합이 지정된 문자열은 변환 대상이 아님
처리 결과를 클라이언트로 전송할 때의 문자 집합 변환
- character_set_connection에 정의된 문자 집합으로 변환해 SQL을 실행한 다음 MySQL 서버는 쿼리의 결과를 character_set_results 변수에 설정된 문자 집합으로 변환해서 클라이언트로 전송한다.
- 결과 셋에 포함된 컬럼의 값이나 컬럼명과 같은 메타데이터는 모두 character_set_results로 인코딩되어 클라이언트로 전송된다.
- 변환 전/후의 문자 집합이 똑같다면 별도의 문자 집합 변환 작업은 모두 생략한다.
콜레이션 (Collation)
- 문자열 컬럼의 값에 대한 비교나 정렬 순서를 위한 규칙
콜레이션 이해
- 하나의 문자 집합에 속한 콜레이션은 다른 문자 집합과 공유해서 사용할 수 없음
- 콜레이션을 지정하지 않으면 디폴트 값으로 지정
- MySQL 서버에서 사용 가능한 콜레이션은
show collation명령으로 확인- 일반적으로 콜레이션의 이름은 2 or 3개의 파트로 구분되어 있음
- 3개의 파트로 구성된 콜레이션
- 첫번째 파트는 문자 집합의 이름
- 두번째 파트는 해당 문자 집합의 하위 분류
- 세번째 파트는 대/소문자 구분 여부
ci이면 대소문자 구분x,cs면 대소문자 구분o
- 2개의 파트로 구성된 콜레이션
- 첫번째 파트는 문자 집합의 이름
- 두번째 파트는
bin- 이진 데이터를 의미, 별도의 콜레이션을 가지지 않음
- 비교 및 정렬은 실제 문자 데이터의 바이트 값 기준으로 수행
utf8mb4- 액센트 문자의 구분 여부 추가 (ai, as)
utf8mb4_0900_ai_ci: 액센트를 가지지 않은 문자utf8mb4_0900_as_ci: 액센트를 가진 문자
- 3개의 파트로 구성된 콜레이션
- 일반적으로 콜레이션의 이름은 2 or 3개의 파트로 구분되어 있음
|
|
- create database 명령으로 기본 문자 집합이 utf8mb4인 db를 생성
- create table 명령에서 각 컬럼이 서로 다른 문자 집합이나 콜레이션을 사용하도록 정의
utf8mb4 문자 집합의 콜레이션
| 콜레이션 | UCA 버전 |
|---|---|
| uf8_unicode_ci | 4.0.0 |
| utf8_unicode_520_ci | 5.2.0 |
| utf8mb4_unicode_520_ci | 5.2.0 |
| utf8mb4_0900_ai_ci | 9.0.0 |
- 숫자 값이 포함되지 않은 콜레이션은 4.0.0버전
- 콜레이션 이름에 Locale이 포함되어 있는지 여부로 언어에 종속적인 콜레이션과 비종속적인 콜레이션으로 구분할 수 있음
- UCA 9.0.0 버전은 이전의 버전보다 빠르다고 MySQL 매뉴얼에서 소개함
- 실제로는 크게 성능 영향은 없음
|
|
- 속도 차이가 크지 않기 때문에 콜레이션 결정 기준을 성능을 기준으로 하기보단 필요에 따라 결정하는 것을 권장
비교 방식
- char, varchar의 비교 방식은 거의 같음
- MySQL 서버에서 지원하는 대부분의 문자 집합과 콜레이션에서 char, varchar 타입을 비교할 때 공백문자를 뒤에 붙여서 문자열의 길이를 동일하게 만든 후 비교
|
|
- utf8mb4 문자집합이 UCA버전 9.0.0을 지원하면서 문자열 뒤 공백에 대한 비교 방식이 달라짐
|
|
|
|
- 문자 집합이 문자열 뒤의 공백이 비교 결과에 영향이 있는지는 information_schema db의 collations 뷰에서 pad_attribute 컬럼의 값으로 판단
pad space로 표시된 콜레이션은 비교 대상 문자열의 길이가 같아지도록 공백을 채움no pad로 표시된 콜레이션은 문자열에 공백을 채우지 않고 그대로 비교- 비교 대상 문자열의 길이가 많이 차이나는 경우 더 빠른 성능
like를 사용한 문자열 패턴 비교는 공백 문자가 유효 문자로 취급됨1 2 3 4 5 6 7 8-- false select 'ABC ' like `ABC`; -- false select ' ABC' like `ABC`; -- true select 'ABC ' like `ABC%`;
문자열 이스케이프 처리
| 이스케이프 표기 | 의미 |
|---|---|
| \0 | ascii null문자 (0x00) |
| \’ | 홑따옴표(') |
| \" | 쌍따옴표(") |
| \b | 백스페이스 문자 |
| \n | 개행문자 |
| \r | 캐리지 리턴 문자 (window에서는 \r\n 조합으로 개행문자 사용) |
| \t | 탭 문자 |
| \\ | 백 슬래시 문자(\) |
| \% | 퍼센트 문자 |
| \_ | 언더 스코어 문자 |
- %, _ 문자는 like를 사용하는 패턴 검색에서만 사용 가능
'"를 두번 연속으로 표기해서 이스케이프 처리할 수 있음
|
|
- 홑/쌍따옴표를 쌍/홑따옴표로 감싸면 이스케이프 처리가 되지 않음
정수
| 데이터 타입 | 저장 공간 (Bytes) | 최솟값(signed) | 최솟값(unsigned) | 최댓값(signed) | 최댓값(unsigned) |
|---|---|---|---|---|---|
| TINYINT | 1 | -128 | 0 | 127 | 255 |
| SMALLINT | 2 | -32768 | 0 | 32767 | 65535 |
| MEDIUMINT | 3 | -8388608 | 0 | 8388607 | 16777215 |
| INT | 4 | -2147483648 | 0 | 2147483647 | 4294967295 |
| BIGINT | 8 | -263 | 0 | 263-1 | 264-1 |
- 정수 타입은 unsigned 옵션 사용 가능
- 명시하지 않으면 signed으로 지정
- auto increment와 같이 음수가 될 수 없는 값을 저장하는 컬럼에 unsigned가 적절
- 외래키로 사용하거나 조인의 조건이 되는 컬럼은 옵션을 일치시키는 것이 좋음
부동 소수점
- float, double 타입을 사용
- 소수점의 위치가 고정적이지 않음
- 숫자값의 길이에 따라 유효범위의 소수점 자릿수가 바뀜
- 근삿값을 저장하는 방식이라 동등 비교는 사용할 수 없음
|
|
- float는 정밀도를 명시하지 않으면 4바이트를 사용해서 유효 자릿수를 8개까지 유지
- 정밀도를 명시하면 최대 8바이트까지 사용가능
- 부동 소수점 값을 저장할 때 유효 소수점의 자릿수만큼 10을 곱해서 정수로 만드는 방법이 있음
DECIMAL
- 금액이나 대출이자 등과 같이 고정된 소수점까지 정확하게 관리해야 할 때 사용
- 이런경우 float, double 타입을 사용하면 안됨
- MySQL에서 소수점 이하의 값까지 정확하게 관리하려면 DECIMAL 타입을 이용해야 한다.
- 숫자 하나를 저장하는데 1/2바이트가 필요하므로 한/두자리를 저장하는데 1바이트가 필요하다.
- 곱셈 연산은 decimal보다 bigint가 더 빠름
- 정수를 관리하기 위해 decimal을 사용하는건 좋지 않음
정수 타입의 컬럼을 생성할 때의 주의사항
- 부동소수점이나 decimal 타입을 이용할 경우 타입의 이름 뒤에 괄호로 정밀도를 표시하는 것이 일반적
- ex
- decimal(20, 5): 정수부를 15자리까지, 소수부를 5자리까지 저장
- decimal(20): 정수부로만 20자리까지 저장
- ex
- decimal은 저장 공간의 크기가 가변적인 데이터 타입이라 저장 가능한 자릿수를 결정함과 동시에 저장 공간의 크기까지 제한한다.
- MySQL 5.7까지는 부동/고정 소수점이 아닌 정수 타입을 생성할 때도 크기를 명시할 수 있는 문법을 지원했음
- MySQL 8.0부터는 정수 타입에 자릿수를 사용하는 기능은 제거됨
- 테이블을 생성할때 bitint(10) 처럼 자릿수를 명시하면 경고메시지를 표시하고 해당 자릿수는 무시됨
자동 증가 (AUTO_INCREMENT) 옵션 사용
- PK를 구성하는 컬럼의 크기가 너무 크거나 PK로 사용할만한 컬럼이 없는 경우 사용
auto_increment_incrementauto_increment_offset시스템 설정으로 자동 증가 값을 설정할 수 있음- ex. auto_increment_offset=5 auto_increment_increment=10이면 5, 15, 25, 35
- 테이블당 하나만 사용 가능
- 다음 증가 값이 얼마인지
show create table명령으로 조회 가능 - auto increment 옵션을 사용한 컬럼은 PK나 유니크 키의 일부로 정의해야 한다.
- PK나 유니크 키가 여러 개의 컬럼으로 구성되면 컬럼값이 증가하는 패턴이 달라짐
- MyISAM: 해당 컬럼이 PK나 유니크 키의 아무 위치에서나 사용될 수 있음
- InnoDB: auto increment 컬럼으로 시작되는 인덱스를 생성해야 함
1 2 3 4 5 6 7 8 9 10 11 12 13 14-- fd_pk2 컬럼이 pk의 뒤쪽에 있어서 에러발생 create table tb_autoinc_innodb ( fd_pk1 int not null default '0', fd_pk2 int not null auto_increment, primary key (fd_pk1, fd_pk2) ) engine=innodb; -- fd_pk2 컬럼이 pk의 뒤쪽에 위치하지만 유니크 키의 맨 앞에 위치하므로 정상적으로 테이블이 생성됨 create table tb_autoinc_innodb ( fd_pk1 int not null default '0', fd_pk2 int not null auto_increment, primary key (fd_pk1, fd_pk2), unique key ux_fdpk2 (fd_pk2) ) engine=innodb;
- PK나 유니크 키가 여러 개의 컬럼으로 구성되면 컬럼값이 증가하는 패턴이 달라짐
날짜와 시간
| 데이터 타입 | MySQL 5.6.4 이전 | MySQL 5.6.4 부터 |
|---|---|---|
| YEAR | 1바이트 | 1바이트 |
| DATE | 3바이트 | 3바이트 |
| TIME | 3바이트 | 3바이트 + (밀리초 단위 저장 공간) |
| DATETIME | 8바이트 | 5바이트 + (밀리초 단위 저장 공간) |
| TIMESTAMP | 4바이트 | 4바이트 + (밀리초 단위 저장 공간) |
| 밀리초 단위 자릿수 | 저장공간 |
|---|---|
| 없음 | 0바이트 |
| 1, 2 | 1바이트 |
| 3, 4 | 2바이트 |
| 5, 6 | 3바이트 |
- 밀리초 단위는 2자리당 1바이트 공간 필요
- ex. MySQL 8.0에서 DATETIME(6) 타입은 5 + 3바이트를 사용
- MySQL의 date, datetime은 컬럼 자체에 타임존 정보가 저장되지 않아서 dbms 커넥션의 타임존과 관계없이 클라이언트로부터 입력된 값을 그대로 저장하고 출력한다.
- timestamp는 항상 UTC 타임존으로 저장되므로 타임존이 달라져도 값이 자동으로 보정된다.
자동 업데이트
- MySQL 5.6 이전까지 timestamp 컬럼은 레코드의 다른 컬럼 데이터가 변경될 때마다 시간이 자동으로 업데이트되고, datetime은 그렇지 않은 차이가 있었음
- MySQL 5.6 부터는 timestamp, datetime 모두 insert, update 문장이 실행될때마다 자동으로 업데이트되기 위한 옵션을 정의해야 함
|
|

Table of Contents
Related Posts
ch15. Data type in DB
ENUM 테이블의 구조에 나열된 목록 중 하나의 값을 가질 수 있다. 1 2 3 4 5 6 create table tb_enum ( fd_enum enum('PROCESSING', 'FAILURE', 'SUCCESS') ); -- 매핑된 문자열이 아닌
2024-3-29
tuple
Problem A “tuple” is defined as an ordered collection of elements which can include duplicate values and each element is assigned an order. A tuple with n elements (a1, a2, a3, ..., an) can be expressed using the set notation in various ways, with any ordering of the subsets as:
2024-5-1
braket rotating
Problem Define a string as a “valid bracket string” if it follows the given rules:
“()”, “[]”, and “{}” are all valid bracket strings. If A is a valid bracket string, then “(A)”, “[A]”, and “{A}” are also valid bracket strings. For example, since “[]” is a valid bracket string, “([])” is also valid.
2024-4-27
Tournament
Problem In the Jay’s game tournament, N players compete in a knockout format. Each player is sequentially assigned a number from 1 to N. The matches are arranged as 1 vs 2, 3 vs 4, …, N-1 vs N. The winner of each game advances to the next round, where they receive new sequential numbers starting from 1 for the advancing players.
2024-4-25
Last and First
Problem Several people are playing the game of English word chain where each player takes turns saying a word that must begin with the last letter of the previous word. Here are the rules:
Players take turns in a sequence from 1 to n. After the last player, it starts again with the first player.
2024-4-23
High Score Kit: Greedy#1
Problem Given a number, your task is to remove k digits from the number in such a way that the remaining digits form the largest possible number. The number is provided as a string number and the integer k represents the number of digits to remove. Your function solution should return the resulting largest number as a string.
2024-4-11
Sponsor
Wechat
Alipay

